Testing fixes for test flakiness
Lean on probability distributions
As part of improving engineering productivity, I help teams deal with flaky tests of Android apps. In this context, here’s how I test and recommend testing fixes for test flakiness.
Flaky Tests
A test is flaky if it provides different verdicts (i.e., PASS v/s FAIL) when repeatedly executed without changing the unit-under-test (UUT) and the test setup/environment.
A flaky test yields different verdicts when repeatedly executed in “identical” environments.
A Common Tactic to deal with Flaky Tests
Since flaky tests seem to be a “standard feature” of software development nowadays, a common tactic to mitigate the ill effects of a flaky test is to repeatedly execute the test until it passes or up to k repetitions (deem the test as passing if it passes in at least one of the k repetitions).
Contrary to its intention of mitigating the effect of flakiness, this tactic does more harm than good. It leads to more resource consumption due to repetition. It reduces engineering velocity due to the waiting on repetitions to complete. Worse yet, it erodes our confidence in tests, i.e., did change X contribute to the flakiness of the test?
Instead of this tactic, the ideal solution is to address the causes of flakiness (e.g., non-determinism, platform influences), which are best covered in dedicated blog posts such as Test Flakiness: Improper Use of Timeouts. Following the ideal solution, once we have a fix to address a cause of flakiness, we encounter the following question.
How can we test a fix for flakiness?
If we expect the fix to eliminate all flakiness from the test, then executing the test once would suffice, i.e., if the fix is effective, the test would pass. However, a test is almost always affected by multiple causes of flakiness, and a fix will often only address some causes. Also, a fix may only reduce the amount of flakiness but not eliminate flakiness, e.g., the ratio of PASS and FAIL verdicts may change from 6:4 to 8:2. So, we will need more than a single execution to test fixes for flakiness.
A simple alternative is to repeatedly execute the test with the fix and check if it yields the PASS verdict in all repetitions, which leads to the following question.
How many repetitions are sufficient to confirm that the fix reduced (or eliminated) flakiness?
The uncertainty associated with failures due to flakiness suggests that we should seek a probabilistic answer to the above question: given the failure rate of the test (due to flakiness), the number of repeated executions of the test in which the failure of at least one execution (due to flakiness) is highly probable.
Lean on Probability Distributions
Definitions
- A Bernoulli trial is an experiment with exactly two outcomes: success and failure, where p is the probability of the success outcome and 1-p is the probability of the failure outcome of the trial.
- In a sequence of independent Bernoulli trials, the probability of the n-th trial yielding the first success outcome follows a geometric distribution, i.e., P(X=n) = ((1-p)**(n-1)) * p where X is the random variable that counts the number of trials needed to obtain the first success outcome. Consequently, the probability of encountering the first success outcome after n trials is given by P(X ≤ n) = 1-((1-p)**n).
Solution
With the above definitions, we can answer the above question as follows.
- Model each repetition of a flaky test as a Bernoulli trial with p as the probability of FAIL verdict (i.e., success outcome) (aka FAIL rate) and 1-p as the probability of PASS verdict, i.e., failure outcome.
- Use geometric distribution to calculate the number of repetitions n of the flaky test required to observe at least one FAIL verdict with the desired level of confidence 0 ≤ c ≤ 1.
Specifically, solve P(X≤n) = 1-((1-p)**n) for n by fixing P(X≤n) = c.
If a fix is effective in reducing flakiness and the FAIL rate prior to the fix was p is the, then the fix should reduce the FAIL rate (due to flakiness) to q < p. Consequently, the fix will reduce the probability of observing a failure due to flakiness in n repetitions when n is calculated based on p. So, if we do not observe a failure due to flakiness in n repetitions, then we can conclude a fix is effective.
An Example
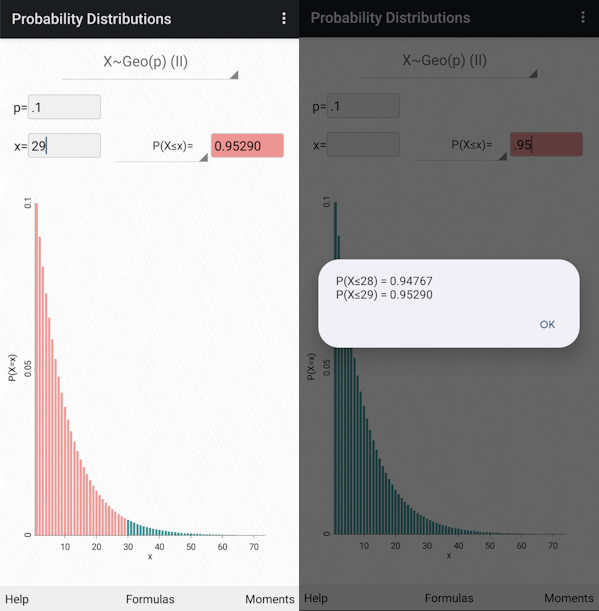
Given a flaky test, we execute the test 100 times without any fixes. If we observe 90 PASS verdicts and 10 FAIL verdicts in these executions, we estimate the probability p of a FAIL verdict as 0.1. If the desired level of confidence c that our fix addressed the cause of flakiness is 0.95, then we solve 0.95 = ((1–0.1)**(n-1)) * 0.1 for n, which will be 29.
With access to R, Octave, or SciPy/Python software, we can easily calculate n using the quantile functions for the geometric distribution: qgeom(0.95, 0.1), geoinv(0.95, 0.1), or scipy.stats.geom.ppf(0.95, 0.1), respectively. We can do the same with probability distribution apps.
A Few Curious Questions
Why not just guess the number of repetitions?
Using fewer than the calculated repetitions will likely not confirm the fix’s efficacy, e.g., if we used 15 repetitions instead of 29 repetitions in the above example, the probability of incorrectly concluding the fix as being effective is 0.14.
Using more than the calculated repetitions will lead to inefficient use of computing resources (and possibly unnecessarily increased confidence), e.g., spinning up 100 Android virtual devices vs spinning up 29 Android virtual devices.
When the test does not fail in n repetitions, are we certain that the fix eliminated flakiness?
No. Given the probabilistic nature of the solution, if the test does not fail in n repetitions, then we can only be highly confident that the fix reduced flakiness.
What if a fix reduces but does not eliminate flakiness?
While the above solution helps confirm that such fixes reduce the FAIL rate p, it does not help determine the reduced FAIL rate due to a fix. To determine the reduced FAIL rate, use the geometric distribution to calculate the number of repetitions n based on the expected FAIL rate (e.g., if the expected FAIL rate is 0.05, then we solve 0.95 = ((1–0.05)**(n-1)) * 0.05 for n) and execute the test n times.
An alternative solution is to use negative binomial (Pascal) distribution instead of geometric distribution in the above approach to account for multiple failures instead of a single failure in n repetitions.
What if a test is affected by multiple causes of flakiness?
When estimating the FAIL rate p, consider only the test failures due to the cause of flakiness being fixed. For example, suppose we observe 20 FAIL verdicts in 100 repetitions while estimating the FAIL rate. If only 12 of these are due to the cause of flakiness being fixed, then we estimate the FAIL rate associated with the cause to be 12 / 100 = 0.12.
While reducing flakiness, how can we target a specific FAIL rate?
Before reducing flakiness, identify the target FAIL rate p and calculate the number of repetitions n to verify p. Then, use n repetitions to confirm that the current FAIL rate (before fixes) is higher than p and that the fixes achieve the target FAIL rate p.
Summary
If you have devised a fix for test flakiness, then test the fix via repeated executions of affected tests. Instead of guessing the number of repetitions, use geometric distribution to determine the number of repetitions to increase your confidence in the effectiveness of the fix.
